In today’s business environment, huge volumes of information have become a critical factor in running organizations. One of the techniques used when dealing with this data is data replication. Backups are also called replication, where data is duplicated to other locations or systems for availability, reliability, and accessibility. In this blog, let us discuss the various approaches to data replication, how they work, and why they are relevant in the present-day IT environment.
What Exactly Is Data Replication?
Data replication is making copies of objects in a database, such as tables or single files, in different locations. This makes certain that similar datasets could be retrieved in other environments or systems which is very essential in matters concerning duplication and validation of data. Since data synchronization has become a norm in various platforms, then it becomes less hard for organizations to deal with data losses and thereby the downtimes. This process is necessary when HA and DR are necessary such as in the cloud, data warehouse, and online transaction processing systems.
The Importance of Data Replication in Modern IT Infrastructure
Replication of data has turned out to be one of the necessary features of the current data scenario to support the structure and integrity of data. When information is dispersed in various regions, organizations get enhanced access and dependability to the business information which enhances business resilience.
One of the uses of data replication is to handle load balancing, where there is a distribution of incoming requests across many servers to reduce the chances of operations being done on a particular server. This is especially important in cases where there is heavy traffic to the application, such as online shopping sites or banking. Additionally, in the event of hardware failures or cyber-attacks, replicated data serves as a safety net, allowing quick restoration of services without significant data loss. This proactive approach ensures business continuity and compliance with stringent data protection regulations.
Synchronous vs. Asynchronous Data Replication Explained
Data replication can be categorized into two main types: synchronous and asynchronous.
Synchronous replication involves copying data to the secondary location in real time. Any changes made to the primary data source are immediately reflected in the replica. This ensures the replicated data is always up-to-date, providing strong consistency and minimal data loss. However, this method can introduce latency issues, especially in high-volume environments where network speeds may be a limiting factor.
In contrast, asynchronous replication operates with a delay between the original data change and the replication process. Updates are batched and sent to the secondary location at scheduled intervals. This approach reduces the performance impact on the primary system and can handle higher volumes of data more efficiently. However, it risks data loss during a failure event, as the replicated data may not include the most recent changes during the disruption.
Full vs. Partial Data Replication: Understanding the Differences
Full data replication involves duplicating the entire dataset from a primary location to one or more secondary locations. This approach has a major benefit when the scope of data access is extensive, for example, for analytical and reporting purposes. However, due to the substantial data volumes involved, full replication can be resource-intensive, demanding considerable bandwidth and storage capacity, especially in environments with large databases.
In contrast, partial data replication focuses on replicating only specific subsets of data crucial for particular applications or workflows. Therefore, this approach is much lighter concerning the resource load and may appeal to organizations with limited storage space or bandwidth only processing the necessary data. Partial replication is especially useful in scenarios where only a fraction of the total dataset is needed, such as for mobile applications or remote access situations where bandwidth may be constrained.
Choosing between full and partial data replication often depends on the specific needs and resource capabilities of an organization. While full replication guarantees that all data is constantly available, partial replication is a more selective and, therefore, more rational approach, helping to save money on resources, but still providing sufficient data availability simultaneously.
Log-Based vs. Snapshot Data Replication
Log-based data replication leverages transaction logs to capture and replicate changes from the primary database continuously. As such, changes are updated in near real-time, making the data most suitable for environments where value updates play a crucial role. The process operates based on all the changes made to the database and storing them in the transaction log file. These logs are then sent back to the target system, where the transactions are played back in a bid to bring it in sync. This approach minimizes the performance impact on the primary database and generally requires fewer resources than other methods.
In contrast, snapshot replication involves capturing a complete image or “snapshot” of the data at predefined intervals. This method was relatively easy to apply and control and, therefore, can be recommended for cases where simplicity becomes a major consideration. However, because snapshot replication only occurs at specific times, it can result in data discrepancies between updates. This delay means that any changes made between snapshots won’t be immediately reflected in the replicated data, which may not be ideal for environments with frequent data updates.
Both log-based and snapshot replication have their distinct advantages and trade-offs. Log-based replication excels in scenarios where real-time data consistency is crucial, and resources are a concern. Snapshot replication, in contrast, is simple to manage and, thus, ideal for applications wherein change is not frequent.
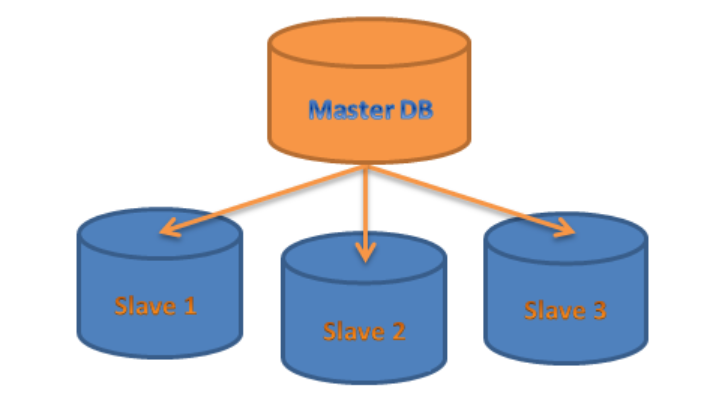
Multi-Master vs. Master-Slave Replication Models
In the master-slave replication model, one primary database (the master) handles all write operations, while one or more secondary databases (enslaved people) are dedicated to read-only operations. This setup simplifies administrative tasks and centralizes write operations, ensuring that updates are consistently applied at a single point. However, it can become a bottleneck in scenarios with heavy read demands, as the master database may struggle to keep up with the volume of write requests, potentially slowing down performance.
Conversely, the multi-master replication model distributes the load by allowing multiple databases to handle write operations concurrently. This model also increases the system availability and load balancing as the write must go to any of the master databases in the system. Nevertheless, as mentioned above, there are a few complications in ensuring master-master consistency.
When there are several master databases, data written to these separate databases can experience conflicts, which call for highly mature conflict resolution protocols. These add more complications to the multi-master replication compared to the master-master replication. Still, the benefits include scalability and fault tolerance, especially advantageous in distributed systems or highly available global applications.
Real-World Applications and Use Cases of Data Replication
Data replication is integral to various industries, enhancing efficiency and reliability. In e-commerce, it ensures seamless synchronization of product information across different platforms and regions, facilitating consistent user experiences and efficient inventory management. Several financial institutions use data replication for real-time transaction processing and backup to ensure that they do not take a long time to restore in the event of a disaster in compliance with set legal requirements. Data replication in health care remains beneficial to provide users – and especially the medical practitioners – constant and real-time access to the medical records
for the delivery of the proper care. This is especially important during such incidences since a physician might need to make a decision, which could be informed by the flowchart or the time taken to get a holistic view of the patient’s status. Data replication is also evident in telecommunication firms to organize customer data in distributed systems for improved service delivery as well as reliability of the telecommunication networks.
For organizations that implement the use of cloud services, data backup is critical to disaster management plans as it is designed to provide operating data in the event of a failure in the primary system. But it also allows load balancing so that through it, firms may handle more traffic than is regular without adverse outcomes.
Big data replication is also used in media and entertainment industries to distribute large files of entertainment media to users around the world. Business institutions benefit from replicated data to enable students and staff access to learning and business materials and information respectively across the education institution’s facility or campuses. Through effective data replication practices, organizations operating in these sectors can thus realize high availability, increased performance, and improved data protection that reflects their organizational objectives and customers.
Choosing the Right Data Replication Strategy for Your Needs
This means that various factors need to be taken into consideration when choosing the appropriate approach to data replication to suit the needs of the organization. Start by determining the degree of importance of data consistency and the extent to which you need your apps to work in real-time. For applications where immediate data updates are essential, synchronous replication might be necessary despite its potential latency issues. On the other hand, asynchronous replication could be more effective for issues that do not require time-sensitive solutions because it provides the right level of performance and data accessibility.
Determine your infrastructure’s throughput and capacity. While ensuring that all data availability is comprehensive, full data replication requires a significant number of resources, which could be very costly to several organizations. Partial replication, on the other hand, can save important bandwidth and storage resources since only data subsets can be copied.
Consider the nature of your applications and their data update frequency. Log-based replication is ideal for environments requiring continuous updates with minimal performance impact, while snapshot replication offers simplicity for less frequently changing data.
Look at the possibilities for potentially solving conflict within the system architecture. Controller–controller replication increases scalability and fault tolerance; however, effective strategies must be developed to resolve conflicts due to concurrent writes. Master-slave replication simplifies administration but may become a bottleneck under heavy load.
Finally, know the needs of that particular industry and the relevant compliance laws in the particular field. Some organizations may need data replication at the sector level where the requirements may differ from one sector to another depending on its nature, such as the finance sector, health sector, and e-commerce sector, among others. If well aligned with such factors, you can implement the right data replication solution to meet the intended objectives of your organization with the set technological environment at your disposal.